
Menjelang hari pencoblosan dalam Pilkada DKI Jakarta, berbagai survei berbasis wawancara lapangan hingga yang berbasis big data analytics bertebaran di berbagai media, baik cetak – tv hingga digital. Masing-masing menebar klaim terunggul dalam menampilkan elektabilitas tiap paslon dengan beragam tujuan yang seringkali tidak murni sciencetific.
Artikel ini secara khusus akan membahas seperti apakah big data analytics dan bagaimana tools ini bekerja dalam riset politik. Saya coba sharing berdasarkan pengalaman akademik dan professional saat membangun data journalism berbasis big data analytics di Media Group sejak 2012.
Perkembangan teknologi informasi yang luar biasa mengubah pola komunikasi yang tadinya satu arah dalam internet 1.0 menjadi memiliki pola komunikasi yang kompleks karena imbuhan kapabilitas untuk sharing (berbagi) dan shout (berkomentar). Di dalam awan internet banyak data penting berserak yang demikian penting dan dapat ditarik dengan mudah dengan crawling system dan dicacah untuk diolah menjadi informasi yang kita inginkan dengan bantuan algoritma tertentu. Untuk menghindari tulisan ini menjadi sangat teknikal computer science, maka penulis coba sederhanakan dengan bahasa awam.
Crawling adalah teknik komputasi untuk menarik data baik berupa data yang tidak terstruktur maupun terstruktur. Bagian paling rumit dari penarikan data dalam Big Data adalah membedakan antara data sampah dengan bukan sampah. Seperti membedakan percakapan dari akun personal yang riel ataukah akun bot yang palsu. Kelebihan dari big data analytic adalah kemampuannya menangkap data secara cepat dan nyaris real time, dibandingkan survei berbasis wawancara yang membutuhkan waktu lebih lama mulai dari rekrutmen pewawancara hingga pengolahan akhir.
Algoritma secara sederhana adalah aturan-aturan matematis yang berisi logika tertentu yang disesuaikan dengan kebutuhan. Algoritma paling biasa digunakan untuk kepentingan riset politik adalah untuk keperluan analisa sentiment. Algoritma paling sederhana dalam sentiment analysis bekerja untuk membedakan tweet-an tersebut bersentimen positif, netral atau negative. Secara advance, sentiment analysis mampu memetakan tidak saja sentiment positif negative, tapi juga sumber (lokasi/waktu/personal), pola sebaran dan konteks yang dibangun.
Sentiment analysis biasanya terdiri dari tahap tokenisasi yaitu system mencatat sambungan url/xml, ciri khusus dari tweet (nama, hashtag) serta menangkap kata-kata kunci. Hasil dari tokenisasi akan diekstrak dan dianalisis serta diklasifikasi dengan beberapa metode seperti yang umum adalah naïve bayes.
 Riset tentang peranan big data dalam riset politik sendiri sudah semakin intens sejak 10 tahun terakhir. Seperti pada grafik di atas merupakan hasil studi dari Brendan O’Connor, Ramnath Balasubramanyan, Bryan R. Routledge, and Noah A. Smith yang dipublikasikan pada 2010. Hasilnya korelasi r menunjukkan kesesuaian antara survei lapangan gallup terhadap tingkat kepercayaan public dengan hasil crawling dan proses sentiment analysis. Secara statistik, hasil ini bisa menjadi dasar untuk memprediksi secara tingkat kepercayaan public dengan menggunakan sentiment analysis berdasarkan keywords tertentu.
Riset tentang peranan big data dalam riset politik sendiri sudah semakin intens sejak 10 tahun terakhir. Seperti pada grafik di atas merupakan hasil studi dari Brendan O’Connor, Ramnath Balasubramanyan, Bryan R. Routledge, and Noah A. Smith yang dipublikasikan pada 2010. Hasilnya korelasi r menunjukkan kesesuaian antara survei lapangan gallup terhadap tingkat kepercayaan public dengan hasil crawling dan proses sentiment analysis. Secara statistik, hasil ini bisa menjadi dasar untuk memprediksi secara tingkat kepercayaan public dengan menggunakan sentiment analysis berdasarkan keywords tertentu.
Untuk konteks Indonesia, big data mulai digunakan dengan intens pada pemilu 2014. Untuk Media Group waktu itu mengembangkan intelligent media monitoring system. Di mana crawling system diajarkan untuk tidak saja mengenali text, tapi mampu membaca audio visual dan mentranslasi ke dalam text untuk kemudian diolah lebih lanjut.
Ada bermacam analisa yang dikembangkan dalam sistem pengolahan data seperti grafik dibawah dengan mengombinasi tag location berbasis GPS dengan percakapan di media social maka big data dapat berbicara soal mapping isu yang berkembang di suatu wilayah sehingga kandidat dengan mudah memahami isu dan menyiapkan scenario narasi yang dikembangkan.
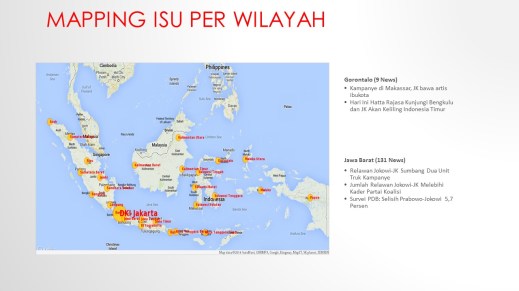
Puncaknya adalah bagaimana system dipersiapkan untuk mampu mengenali percakapan-percakapan yang mencerminkan elektabilitas atau preferensi politik public. Kelebihan big data adalah mampu merekam data dan memetakan tweet-an atau opini pribadi di media social dengan massive layaknya sebuah survei lapangan quick count.
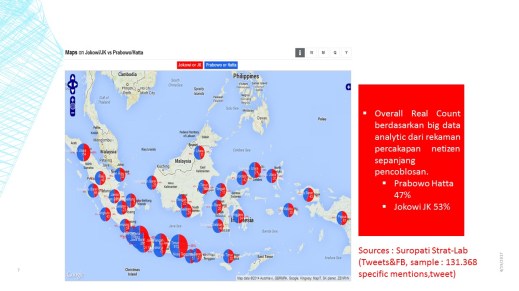
Hasilnya luar biasa. perbedaan dengan real count KPU waktu itu kurang dari 1% dan system langsung bisa mempublikasi data dalam jumlah sampel yang solid dalam tempo kurang dari 1 jam saat TPS sudah ditutup dan proses penghitungan masih berlangsung.
Apakah hal serupa bisa diterapkan di pilkada DKI Jakarta? Jawabnya, iya. Lalu bagaimana dengan tingkat akurasi, maka jawabannya berbeda dengan kasus 2014.
2014 adalah periode di mana euphoria volunteerism politik pertama kali menggelora tidak berbasis pada ideologi politik yang dilahirkan partai. Tapi berbasis personifikasi seorang kandidat waktu itu yang diasosiasikan sebagai orang biasa, non-elite yang mengusung mimpi kebanyakan orang. Demikian euforianya membuat ekspresi public dalam beragam saluran komunikasi demikian terbukanya. Sebuah populasi yang empuk dijadikan lahan Big Data System untuk memotret dan mengolah datanya.
Fenomena pilkada DKI sangat berbeda terutama situasi politik yang kental atmosfer intimidasi psikologis berbasis agama. Bahkan tidak tanggung-tanggung, isu yang berkembang belakangan menjurus pada penghilangan hak-hak keagamaan tertentu bagi kelompok yang berbeda pendapat dan pilihan politik. Dan ini cukup membuat ekspresi publik menjadi tertutup. Ada sekelompok besar dalam populasi yang memilih enggan konfrontasi dengan lingkungan yang sedang memanas sehingga menyembunyikan ekspresinya lebih implisit. Ramalan berbasis beberapa pencuplikan data di beberapa momen penting seperti 4 November 2016, 2 Desember 2016 bahkan saat pencoblosan putaran pertama, bias dari situasi ini melahirkan rentang kesalahan ukur hingga 3%.
Meskipun demikian terdapat beberapa lembaga mengeluarkan ramalan mereka terkait elektabilitas dan pola komunikasi antar kandidat seperti di bawah ini.


Data per tulisan ini dipublikasikan jika dari versi saya, maka tingkat elektabilitas Anies-Sandi di 51,3% berbanding Ahok-Djarot di 48,7%. Dan dengan tingkat galat error 3%, maka bisa dikatakan, Pilkada DKI ini masih menyisakan situasi deg-degan setidaknya hingga real count dipublikasikan oleh KPUD DKI Jakarta.
Maaf kalau ramalannya agak nanggung. Ternyata Big Data Analytics itu sama saja dengan alat ukur lain. Dia sangat bergantung pada kualitas jawaban sample-nya. Dan khusus Big Data, kualitas sample terletak pada ekspresi dan konteks lingkungan di mana komunikasi itu tercipta.
Selamat deg-degan untuk kandidat dan timsesnya!
